Au-delà de l’Open Data : l’enjeu de la mise en réseau
Le modèle fondamental de l’économie numérique est un réseau. De l’architecture même d’Internet, dont le design fait croître robustesse et fiabilité avec le nombre de noeuds, à Facebook dont l’intérêt pour un individu croît en fonction du nombre de ses amis présents.
Au coeur du numérique, le réseau
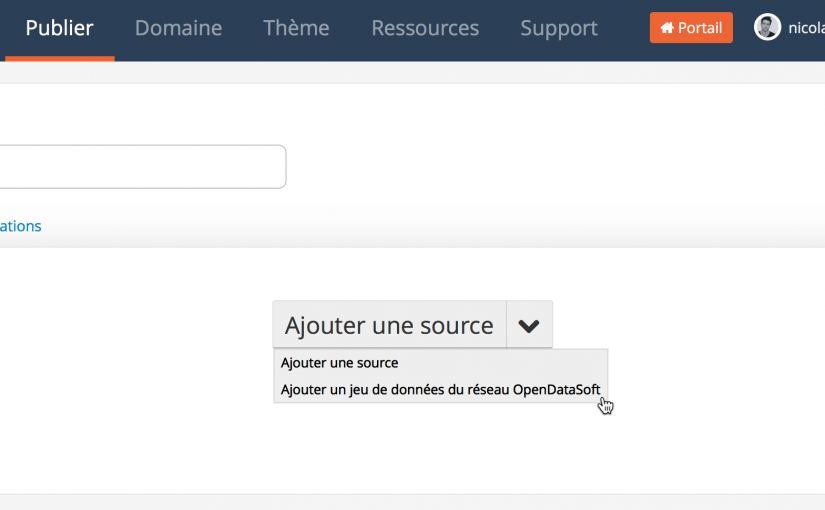
C’est pour cette raison que nous permettons maintenant à nos utilisateurs d’ajouter une source de données du réseau OpenDataSoft. Concrètement il est maintenant possible de récupérer tous les jeux de données ouverts par l’ensemble de nos clients. Le tout sans duplication, sans perdre les méta-données, sans risque de sécurité et en ayant la possibilité de filtrer une partie des données.
Cette possibilité facilite encore plus la réutilisation des données du producteur – ce qui est généralement un des objectifs d’une démarche Open Data. Elle rend aussi encore plus évident, à tout un chacun – notamment avec un compte gratuit OpenDataSoft – de profiter des outils de cartographie, de création de graphiques et de widgets afin de découvrir les données. Encore une fois, OpenDataSoft raccourcit le chemin entre la publication d’un jeu de données et la création de services à partir de ces données par n’importe qui.
Ce réseau de jeux de données laisse envisager de nouveaux modèles de distribution de données très enthousiasmants.
MaVille, une génération automatique de portails permise par le réseau
Avec la Loi NOTRe votée, un grand nombre de communes françaises vont être amenées à faire un effort de publication de données. Nous avons donc tenté de faire un premier pas en générant automatiquement les portails des villes de plus de 20 000 habitants.
Pour cela, il nous a suffit de faire une recherche sur data.opendatasoft.com pour trouver des données à la granularité “commune”. De la démographie à la couverture 4G en passant par les offres d’emploi, une multitude de jeux de données peuvent être utiles aux citoyens sans qu’ils aient forcément envie d’aller chercher eux-mêmes à l’intérieur du jeu de données.
Il nous a alors suffit pour chaque portail d’ajouter une source du réseau OpenDataSoft, de filtrer par le code INSEE de la commune et d’avoir une page d’accueil par défaut reprenant les principales informations = l’histoire de quelques copier-coller avec nos widgets !
Maintenant, imaginons que :
- viennent s’ajouter à cette démarche des données de grands groupes industriels,
- que n’importe quel citoyen puisse s’inspirer de notre initiative et créer son propre tableau de bord,
- que les différents échelons administratifs aient une cohérence par défaut dans leurs démarches d’ouvertures de données respectives,
- que la comparaison, et donc l’émulation, entre organisations soit rapide et sans embûche technologique pour n’importe quelle entité,
- que tout ceci se fasse sans perte d’information quand les données sont mises à jour pour la simple et bonne raison qu’il n’y a qu’un unique jeu de données qui sert tous ces usages,
alors, on commence à apercevoir les effets de réseaux et les synergies possibles dans le monde des données.
L’essor global de l’Open Data
L’Open Data avance, et plutôt vite. Il suffit de comparer avec les premiers portails qui ne proposaient que des listes de liens de téléchargement – comme Amazon fut un jour une simple liste HTML de livres. Avec la multiplication des ouvertures de données et de leurs réutilisateurs, les solutions évoluent et des gains d’efficacité se font à tous les niveaux de la chaine de valeur.
Les velléités de recherche d’effets de réseaux dans les données sont loin d’être récentes. Le mouvement des données liées et du web sémantique en sont l’exemple le plus fort. Si nous pensons que cette vision est très forte et porteuse de beaucoup d’intérêt, deux raisons nous semblent encore être des freins :
- Nettoyer et préparer des données liées reste encore un travail d’experts dans la plupart des cas et demande beaucoup de temps. Cela va évoluer avec la multiplication d’outils et de définitions d’ontologies claires mais c’est encore une tâche non-industrialisable.
- L’interrogation et l’analyse des données restent encore bloquantes pour beaucoup de personnes. Le langage de requête SPARQL est réellement puissant et permet de s’approprier la donnée en en comprenant la structure. Mais SPARQL requiert un apprentissage, et les outils permettant à tout un chacun d’en profiter n’existent pas encore.
Le web sémantique est clairement une inspiration pour nous et ce réseau de jeux de données est une première étape. Très prochainement en effet, OpenDataSoft permettra de lier les données, et les jeux de données ouverts du réseau viendront alimenter le web des data.
OpenDataSoft a toujours voulu rendre les données, leur diffusion et leur réutilisation accessibles au plus grand nombre, multipliant les efforts pour fournir des outils accessibles ne nécessitant quasiment pas d’apprentissage. Faciliter encore plus l’accès aux données Open Data permet d’avancer sur ces trois aspects à la fois.
Vous souhaitez ouvrir vos données ?
Recevez votre guide gratuit maintenant ! Il réunit les 10 étapes essentielles pour bien amorcer votre projet Open Data.
Source : ADEC - Open data